Psephology
Psephology plays a constructive role in all democratic countries, finding answers to vital political-electoral patterns and deviations impacting the propaganda of parties and individuals.
The psephology pseudoscience comes to play before and during an election, influencing the campaign agenda and reach to the diverse cultural, linguistic, ethnic and religious audience. Given the size of the country and population, our team of psephologist’s uses impartial and sophisticated prediction models to get the big picture in a scientific way.
Our psephologist’s team proficiently balances the statistical approach with an eye for detail, past and current election affair, demographic patterns, caste gender dynamics, region/area influence with a sharp political sense. The team collects and analyses election’s facts, figures and public opinion polls before arriving at a conclusion. The analysis encompasses critical aspects viz., voting trends, vote swings, percentage and number of votes polled, which translate directly into number of seats in a government.
Opinion polls and surveys directly influence electoral behavior and hence the predictions too, giving heads up on the constellation of candidates and contours of political trends. The unbiased knowledge comes from years of extensive travel and public relations in understanding the primordial voting patterns considering region, religion, caste, gender and age loyalties.
Before commissioning a survey, our psephologist team concludes on the questions to ask, size of the survey and the target audience. The end result lies in the knack for neutral interpretation and analyzing the compiled data correctly.
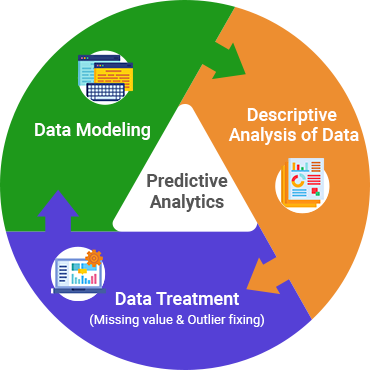
Predictive analytics
Our psephology team understands, plans and executes the strategic predictive analysis with ease and precision of year long experience.
1. Descriptive Analysis of Data
Our team uses advanced machine learning tools to reduce the time taken for feature engineering and descriptive analysis, making more time to identify the missing values and big features.
2. Data Treatment (Missing value & Outlier fixing)
Obvious trends become visible when we use simple, smart and intelligent techniques to extract information, improve efficiency in recognizing missing values and imputing with variables in iterations.
3. Data Modeling
More efficient and effective model is to identify a suitable data model based on the data volume viz., GBM, Random Forest etc. The models are chosen to interpret multicollinear & non-normally distributed data as well.
Our data scientists bring in leadership and contribute to efficient predictions with their clarity in treatment of Data Cleaning, Dimensionality Reduction, Data Optimisation, Noise Reduction, Model Preparation, Predictive Algorithms etc